

Duplicate content is an issue for SEO because it forces search engines to choose between competing versions of the same page, splitting your ranking signals, diluting link authority, wasting your crawl budget, and ultimately preventing any single page from reaching its full ranking potential. If you have been struggling to climb the search results despite strong content output, duplicate content may be the silent force working against you right now.
This guide explains exactly what duplicate content is, why it damages your organic visibility, and how to fix it before it costs you traffic and conversions.
What Is Duplicate Content in SEO?
In SEO, duplicate content refers to blocks of text that are either word-for-word identical or substantially similar across two or more URLs, whether those URLs live on your own domain or on completely different websites. It is content that is identical or substantially similar and appears on more than one URL, either within the same site or across different domains. From a search engine perspective, duplicate content is not about intent or wrongdoing. It is about efficiency and clarity.
There are two primary forms you need to understand.
Internal duplicate content happens when multiple pages on your own website contain the same or near-identical material. This is by far the most common and damaging version, because your own pages end up competing against each other in the same search results.
External duplicate content occurs when your content appears on other domains, such as through content syndication, scraping, or republication without proper canonical signals. Content syndicated or scraped across various domains leads to external duplicate content issues.
Both types create confusion for search engines, but internal duplication is almost always the bigger threat to your organic performance.
Why Is Having Duplicate Content an Issue for SEO? The Core Problems
1. Search Engines Cannot Decide Which Page to Rank
This is the most immediate consequence of duplicate content. When multiple pages have the same or very similar content, search engines struggle to determine which version is more relevant or authoritative, leading to potential confusion on which version to index or rank higher.
Think of it this way: if you label every drawer in your dresser “socks,” neither you nor anyone else knows which one actually holds what you need. Search engines like Google will not know which page to index, which page should rank for organic search results, or which duplicate page URL to attribute page authority and link equity to.
When Google cannot determine a clear winner, it may rank a page you did not intend to rank, such as a product filter variant or a printer-friendly version, instead of your primary, conversion-focused page.
2. Link Equity Gets Diluted Across Multiple URLs
Backlinks are one of the most powerful ranking signals in SEO. Every time an external website links to your content, it passes authority to that specific URL. When duplicate content scatters that same material across multiple pages, those valuable backlinks get divided rather than consolidated.
Backlinks and social shares get distributed across multiple versions of your content instead of building authority for a single, definitive page. This weakens your overall domain authority and topic expertise signals.
When websites consolidate cannibalized pages through 301 redirects, they frequently see traffic increases of 100 to 400 percent over several weeks. That figure alone tells you just how much ranking power is being lost when link equity is fragmented.
3. Crawl Budget Is Wasted on Pages That Add No Value
Search engines allocate a limited crawl budget to each website. Duplicate content consumes this budget inefficiently, preventing search engines from discovering and indexing new, valuable content.
For small sites, wasted crawl budget is an inconvenience. For large ecommerce stores, news publishers, or enterprise websites with thousands of pages, it can mean important new content goes unindexed for weeks or even months. Nearly 29 percent of websites have duplicate content issues, meaning nearly one in three businesses are unknowingly sabotaging their own SEO efforts.

4. Keyword Cannibalization Destroys Your Ranking Potential
Near-duplicate content can compete in search engine results for one and the same keywords, a problem known as keyword cannibalization. If Google recognizes the pages as identical or interchangeable, it may choose to omit one of the two pages. In doing so, Google may omit the wrong page.
Keyword cannibalization means your pages are fighting each other instead of outranking your actual competitors. Instead of one strong authoritative page dominating page one, you end up with several weak pages that barely appear at all.
5. Poor User Experience Increases Bounce Rates
Users experience real confusion when encountering duplicate content. This frustration results in poor user experience, negatively impacting your site’s reputation and increasing bounce rates. Google tracks behavioral signals including time on page, return visits, and engagement. When users land on redundant content and immediately leave, those negative signals further suppress your rankings over time.
6. Google May Index the Wrong Version
Google will rank the most appropriate web page, which might not be the version you want to rank for. This creates poor user experience as organic traffic might be directed to a page you have not optimised for visitors or linked internally. This is especially painful for ecommerce businesses where a product filter URL ranks instead of the primary product page, sending shoppers to a broken or unoptimized experience.
Does Duplicate Content Hurt SEO? What Google Actually Says
Here is where many site owners get confused. Duplicate content does not automatically trigger a Google penalty. However, it can become a manual issue in rare cases involving thin duplication, doorway pages, or intentionally manipulative duplication designed to dominate search results.
So the famous “duplicate content penalty” is largely a myth for unintentional duplication. The real damage is more subtle and more dangerous: duplicate content does not usually cause rankings to drop overnight. Instead, it weakens SEO performance over time. When similar pages exist, ranking signals such as links, internal links, and relevance are split across URLs instead of being consolidated.
The practical reality is this: Google silently filters your duplicate pages, chooses the version it prefers (which may not be your preferred version), and the rest of your work gets suppressed. No alarm goes off. No notification arrives. Your traffic just quietly declines.
In extreme cases involving intentional scraping or spam-scale duplication, Google has said that content duplication can lead to a penalty or complete deindexing of a website, though this is extremely rare and only done in cases where a site is purposely scraping or copying content from other sites.
How Does Duplicate Content Affect SEO at Scale?
The impact compounds based on the size of your website.
For small business websites, duplicate content might mean two or three pages competing for the same keyword, resulting in inconsistent rankings and lower-than-expected traffic.
For ecommerce sites, the problem multiplies rapidly. Ecommerce sites are especially vulnerable to duplicate content issues because filters and faceted navigation can generate large numbers of similar pages with only minor URL variations. URL parameters and tracking codes often compound the problem by creating multiple versions of the same page without adding any real value for users or search engines.
For enterprise websites and franchise networks, the consequences are exponential. When multiple group entities target the same keywords with similar content, they compete against themselves in search results. This internal competition signals to search engines that the group lacks content differentiation and authority focus.
Regardless of site size, the core effects remain the same: split authority, wasted crawl resources, ranking instability, and reduced organic traffic.
Common Causes of Duplicate Content in SEO You Need to Know
Understanding the sources of duplication is the first step to preventing it. Most duplicate content problems are completely unintentional and stem from technical architecture decisions rather than content laziness.
URL Parameter Variations Tracking codes, session IDs, sorting parameters, and filter options all create new URLs for the same underlying content. A single product page can generate dozens of technically distinct URLs, each with nearly identical material.
WWW vs. Non-WWW and HTTP vs. HTTPS If the WWW version of your website does not redirect to the non-WWW version, this creates duplicate site versions. The same issue appears if you switched your site to HTTPS and did not redirect the HTTP version.
Printer-Friendly Pages Creating a separate printer-friendly version of content without a canonical tag generates a near-identical duplicate that search engines may choose to rank over your primary page.
Pagination Problems Blog archive pages, category pages, and paginated product listings often share identical introductory text and enough content overlap to trigger duplication signals.
Syndicated Content Republishing your content on other sites can cause search engines to misidentify the original source, leading to the syndicated version outranking yours. This is particularly damaging for publishers who contribute content to larger media outlets without proper canonical attribution.
Thin Product Descriptions Using manufacturer-provided product descriptions across ecommerce pages is one of the most widespread sources of external duplication, leaving your site blending in with dozens of competitors serving identical content.
CMS-Generated Tag and Category Pages Content management systems automatically create tag pages, author archives, and category listings that pull in the same post excerpts and descriptions repeatedly, generating significant internal overlap.

How to Avoid Duplicate Content in SEO: Proven Solutions
Use Canonical Tags to Signal the Preferred Page
A canonical tag is an HTML element placed in the head of a webpage that tells search engines which version of a page is the primary one. When implemented correctly, canonical tags give search engines clear guidance on which URL represents the primary version of a page. This allows you to preserve link equity, consolidate ranking signals, and reduce index bloat.
Every page on your site should include a self-referencing canonical tag. This simple step protects you from scrapers republishing your content, because if they copy your HTML, they carry your canonical attribution with them, and Google credits the original.
Critical implementation note: never combine canonical tags with noindex. A canonical page should always be crawlable and indexable.
Implement 301 Redirects for Consolidated Pages
301 redirects permanently move duplicate content to canonical URLs, transferring approximately 90 to 99 percent of ranking authority. Use 301 redirects when duplicate pages serve no legitimate user purpose and can be eliminated entirely.
This approach is the most powerful signal you can send to search engines. When you redirect multiple similar pages to one authoritative URL, all the backlink equity, ranking signals, and crawl priority consolidates on that single page, often producing rapid ranking improvements.
Apply Noindex Tags to Low-Value Pages
Noindex tags remove duplicate pages from search results while keeping them accessible to users. Combine noindex with follow tags to prevent indexing while preserving link equity flow to other pages.
This approach is ideal for filtered product pages, thank-you pages, internal search results, and tag archives that have no unique SEO value but must remain accessible for functional reasons.
Consolidate Thin and Similar Content Into Pillar Pages
Rather than maintaining three blog posts that cover overlapping ground, merge them into one comprehensive, authoritative resource. Content consolidation merges overlapping pages into one comprehensive resource. This avoids keyword cannibalization and creates a stronger, single-page site.
This is one of the fastest ways to see measurable ranking improvements. By concentrating your topic authority into one well-structured page, you stop your own content from working against itself.
Standardize Your URL Structure Site-Wide
Decide on a preferred domain format (www vs. non-www, HTTPS, trailing slash rules) and enforce automatic redirects to that version across your entire site. Configure your content management system to prevent common duplication scenarios. Set preferred domain versions and implement automatic redirects to canonical versions. Configure CMS settings to generate unique meta titles and descriptions for each page, preventing metadata duplication.
Use Google Search Console to Monitor Duplication
Google Search Console provides valuable insights into duplicate content issues. Check the Coverage report for excluded pages marked as “Duplicate without user-selected canonical” or “Duplicate, Google chose different canonical than user.”
These flags are direct signals from Google telling you that it found competing versions of your pages and made its own decision about which one to rank. Those decisions may not align with your SEO strategy.
Read About: What’s the Difference Between On Page and Off Page SEO?
How to Fix Duplicate Content Issues: A Step-by-Step Audit Process
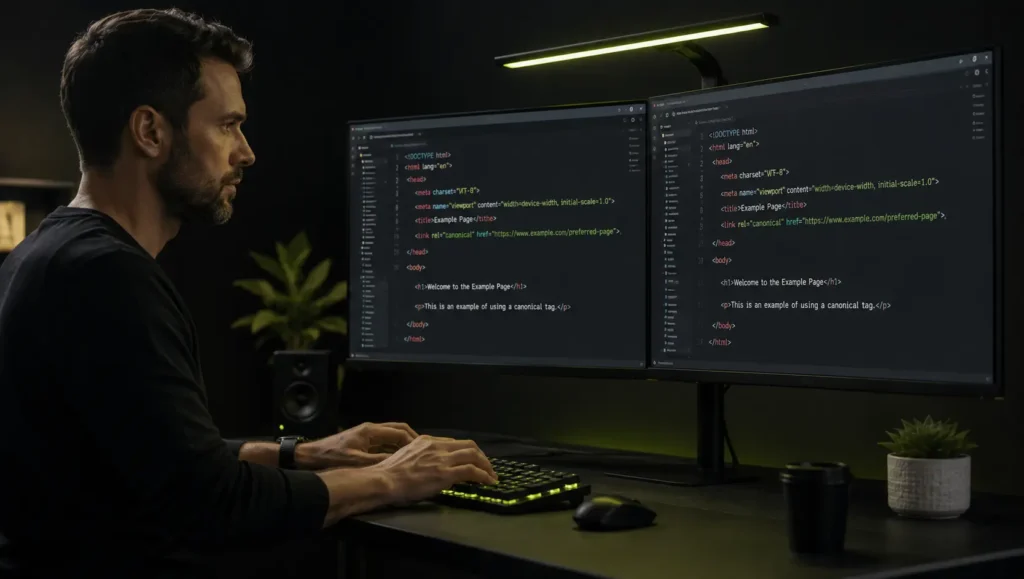
Step 1: Run a Site Crawl Tools like Screaming Frog, Sitebulb, or Ahrefs Site Audit will surface duplicate titles, meta descriptions, and near-identical page content across your domain. For sites under 500 URLs, Screaming Frog’s free plan is sufficient.
Step 2: Review Google Search Console Coverage Reports Look specifically for “Duplicate without user-selected canonical” and “Duplicate, Google chose different canonical than user” statuses. These pages are actively competing for rankings you are not controlling.
Step 3: Identify the Primary URL for Each Duplicate Set For each group of duplicate or near-duplicate pages, determine which URL should serve as the canonical version. This should be the page with the strongest content, the most backlinks, and the best conversion performance.
Step 4: Apply the Appropriate Fix Use a 301 redirect if the duplicate URL has no independent value and can be permanently eliminated. Use a canonical tag if the duplicate must remain accessible for users but should not compete in rankings. Apply a noindex tag for pages with no unique value that need to stay available for functional purposes.
Step 5: Update Internal Links After redirecting or canonicalizing pages, update all internal links site-wide to point directly to the canonical URL. This prevents unnecessary redirect chains and concentrates crawl budget on your preferred pages.
Step 6: Schedule Quarterly Audits For most sites, a quarterly duplicate content check is sufficient. Large ecommerce sites or publishers might need monthly reviews. Duplicate content is not a one-time fix. It re-emerges naturally as sites grow, migrate, and add new content.
How Bad Is Duplicate Content for SEO? Real Business Impact
The question of how bad is duplicate content for SEO is best answered in outcomes rather than theory.
Some sites have reported a 20 percent increase in organic traffic after effectively managing duplicate content. Others, particularly ecommerce businesses dealing with parameter-driven duplication, have seen gains far beyond that after consolidating competing URLs.
In some cases, businesses lose 30 to 50 percent of their potential organic traffic due to duplicate content issues. For an established website generating meaningful revenue from organic search, that represents a substantial and entirely preventable loss.
Beyond traffic, duplicate content affects:
Domain authority by fragmenting the authority signals that build over months and years of link-building effort.
Indexation efficiency by forcing search engine crawlers to spend their limited budget on redundant pages rather than new content you want ranked.
Conversion rates by routing users to unoptimized pages that do not reflect your intended user journey.
Analytics accuracy by splitting session data across multiple URLs, making it difficult to understand which pages are truly performing.
Duplicate Content and AI Search: A Growing Concern
In 2025 and beyond, the impact of duplicate content extends beyond traditional search rankings. Duplicate content can reduce your visibility in AI search engines. When your content is fragmented across multiple URLs, AI systems struggle to identify your site as the definitive source. This reduces your chances of being cited in AI-generated responses. Consolidating your content helps establish clear authority signals for both traditional and AI search.
As generative AI tools like ChatGPT, Perplexity, and Google’s AI Overviews become primary discovery channels, being recognized as the authoritative, original source of information becomes even more critical. Fragmented, duplicated content sends the opposite signal.
Frequently Asked Questions
Does duplicate content hurt SEO even if it was unintentional?
Yes. Duplicate content can hurt rankings indirectly whether it was created deliberately or accidentally. While Google does not usually apply a direct penalty, it dilutes link equity, wastes crawl budget, confuses search engines, and reduces indexing efficiency and ranking power. The intent behind the duplication does not protect you from its consequences.
Does duplicate content affect SEO differently for large ecommerce sites?
Absolutely. Large ecommerce sites face the most severe impact because product filter pages, sorting options, and URL parameters can generate hundreds or thousands of near-identical pages at scale. A single product category with ten filter combinations produces ten competing URLs, each fragmenting the authority that should flow to a single canonical product page.
What is the difference between a canonical tag and a 301 redirect for duplicate content?
A 301 redirect permanently moves one URL to another and consolidates all ranking signals to the destination. A canonical tag identifies the preferred version of a page but keeps both URLs accessible. Use 301 redirects for permanent consolidation. Use canonical tags when duplicates are necessary, such as product variants, printer-friendly
Why is duplicate content bad for SEO even when the content quality is high?
Quality does not override duplication. Even excellent content spread across multiple URLs will underperform because search engines split all ranking signals between those URLs. A single well-canonicalized page with that same content will accumulate authority far more efficiently and rank significantly higher over time.
How do I know if my site has duplicate content problems?
Start with Google Search Console and look for “Coverage” issues flagging duplicate canonical statuses. Then run a crawl using Screaming Frog or a similar tool and filter for duplicate title tags, meta descriptions, and near-identical page content. Also perform a site search using site:yourdomain.com “exact phrase from your page” to surface pages sharing identical text blocks.
Is syndicated content considered duplicate content in SEO?
It is important to distinguish duplication from syndication. Syndicated content is intentionally republished with proper attribution, canonicals, or links to the original source and does not inherently create SEO duplicate content issues when managed correctly. The key is always implementing a canonical tag pointing back to the original source when your content is republished
How to fix duplicate content issues according to Moz and industry best practice?
The three core solutions endorsed by Moz and the broader SEO community are canonical tags (to signal preferred versions), 301 redirects (to permanently consolidate duplicate URLs), and noindex tags (to remove low-value pages from the index without deleting them). Using canonical tags, 301 redirects, and inclusion in XML Sitemaps are ways to specify canonical URLs to search engines, which should be aligned to send consistent signals about which versions of your content deserve priority.
How often should I check my site for duplicate content?
Conduct a formal duplicate content audit every three months. Run additional checks immediately after site migrations, CMS updates, new content campaigns, or any technical changes to URL structure. Duplicate content tends to re-emerge naturally as sites evolve.
Summary: Why Is Having Duplicate Content an Issue for SEO?
Duplicate content is an issue for SEO because it creates a fundamental problem for search engines trying to serve users the best possible result. When the same content lives at multiple URLs, search engines must guess which version matters, and that guessing process fragments your authority, wastes your crawl budget, triggers keyword cannibalization, and depresses your rankings over time.
The good news is that most duplicate content problems are entirely fixable. Canonical tags, 301 redirects, noindex directives, and consistent content consolidation practices are all proven techniques that restore ranking clarity and allow your strongest pages to perform at their full potential.
If you have not yet audited your site for duplication, the data is clear: one in three websites is currently losing organic traffic to this exact problem. A systematic audit followed by targeted fixes is one of the highest-return technical SEO investments you can make, often delivering ranking improvements within weeks of implementation.

Wali Shah is the Founder and CEO of SkillsHeaven, a digital growth agency specializing in Local SEO, Google Ads, and conversion-focused website development. With over 8+ years of experience, he has helped scale 170+ businesses, including 93+ limousine companies globally, by building structured, lead-generating digital systems. His expertise spans local search optimization, paid media strategy, and high-performance website development, all aligned with measurable business growth. Known for a data-driven and ethical approach, Wali focuses on creating scalable marketing systems that increase visibility, generate qualified leads, and drive long-term revenue for service-based businesses.
